爬取指定公众号历史文章并打包存起来,这个 idea 并不新鲜,网上搜搜就能找到许多提供这样服务的。只是这些价格都特别贵,也不能满足自己特殊的需求。
去年年底我用 Python 实现了这一项目,这里写篇博文分享一下思路和遇到的坑。(凑数)
思路
搜一下“爬取公众号历史文章”,能看到的思路差不多一下几种:
- 搜狗搜索
- 公众号资料页面历史文章列表
- 公众号后台群发时插入链接处搜索,思路看这里
简单评估下,以上方法中,1 的缺点是文章不全,得到的链接不是长期有效的(似乎只有短短 24 小时),且需要应对搜狗的反爬,直接 pass。
2 是一个可操作的思路。具体来讲,这个历史文章页面的链接里:biz 是该公众号的标识符,uin 自己微信的标识,key 来自微信特殊的生成算法,对于某一公众号该参数短时间内是持续有效的。思路就很明确了,手动获取到这个页面链接,放进 Selenium 或者直接 requests 一把梭。还有种思路是电脑上配置好 mitmproxy 代理,微信PC版打开此页面,使用 Python 抓包拦截。这是个好思路,快速且安全(不会被限制爬取)。
3 上面“思路参考”页面使用的是 Selenium 操作公众号后台群发页面,也可以尝试直接模拟请求,虽然效率上的提升并不会很明显(请求要限频,否则会封一天),但是少了依赖,实现起来也舒服一些(其实是我前端基础太差……)。这个方法需要一个公众号账户(可以用个人订阅号),相较以上方法门槛高了一点。
取文章链接的实现
基于方法 3,这里写一下 Python 实现(就贴几个流程和请求。代码写的太烂不好意思发)。
登录
baseUrl = 'https://mp.weixin.qq.com' # base
startLoginUrl = '/cgi-bin/bizlogin?action=startlogin' # 提交邮箱、密码,请求登录
validateUrl = '/cgi-bin/bizlogin?action=validate&lang=zh_CN&account=邮箱' # 先请求一次该页面
getQrcodeUrl = '/cgi-bin/loginqrcode?action=getqrcode¶m=4300&rd=三位随机数' # 再取二维码图片
askLoginUrl = '/cgi-bin/loginqrcode?action=ask&token=&lang=zh_CN&f=json&ajax=1' # 持续检测用户扫码结果(0 未扫,1 已扫可以跳转,4 已扫尚未确认)
loginUrl = '/cgi-bin/bizlogin?action=login' # 最终登录,然后访问一下平台首页,页面里可以找到 token根据名称搜索公众号
baseUrl = 'https://mp.weixin.qq.com' # base
searchAccountUrl = '/cgi-bin/searchbiz?action=search_biz&token=鉴权的token&lang=zh_CN&f=json&ajax=1&random=三位随机数' # 参数 query 是查询关键词。返回结果有多个。获取公众号历史文章列表
终于到正题了……
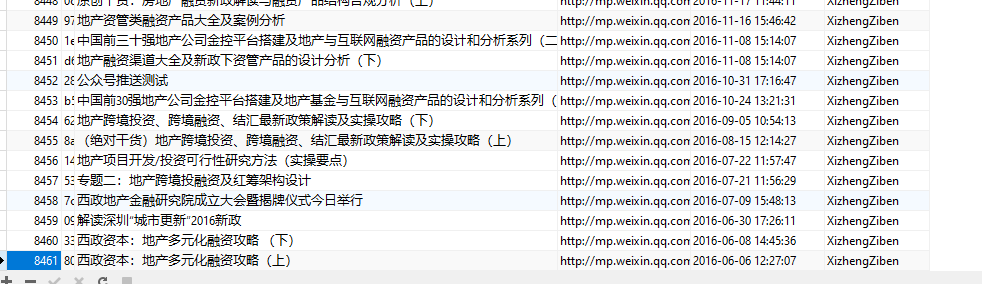
打包生成文档
看下结果好了,Python 写 word。网络上很多介绍了。
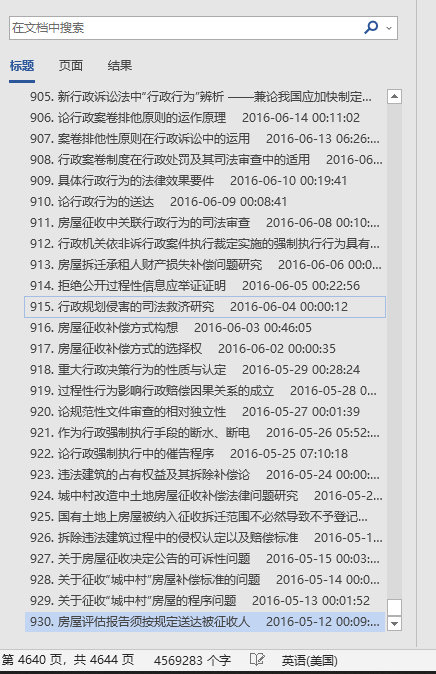
待续
接触 Python 一年多了,写爬虫也有了些经验。
虽然我前端还是菜得一塌糊涂,js 也看不懂,但这不影响我直接看浏览器开发者工具呀。
不会的操作就换个路子实现,虽然一般情况下实现得并不那么优雅。。。
休息。。。待续。